So, here's a thing I made.
I was recently doing some motion graphics work in Nuke, as I do. I had several elements in a shot that I needed to animate-on with the same motion, speed, size, etc.
The graphics were already in their "final" positions, having done a full layout before animating. Now, I just wanted to add an animated Transform to each element. And I wanted to be able to easily adjust them all, together, as I finessed the animation.
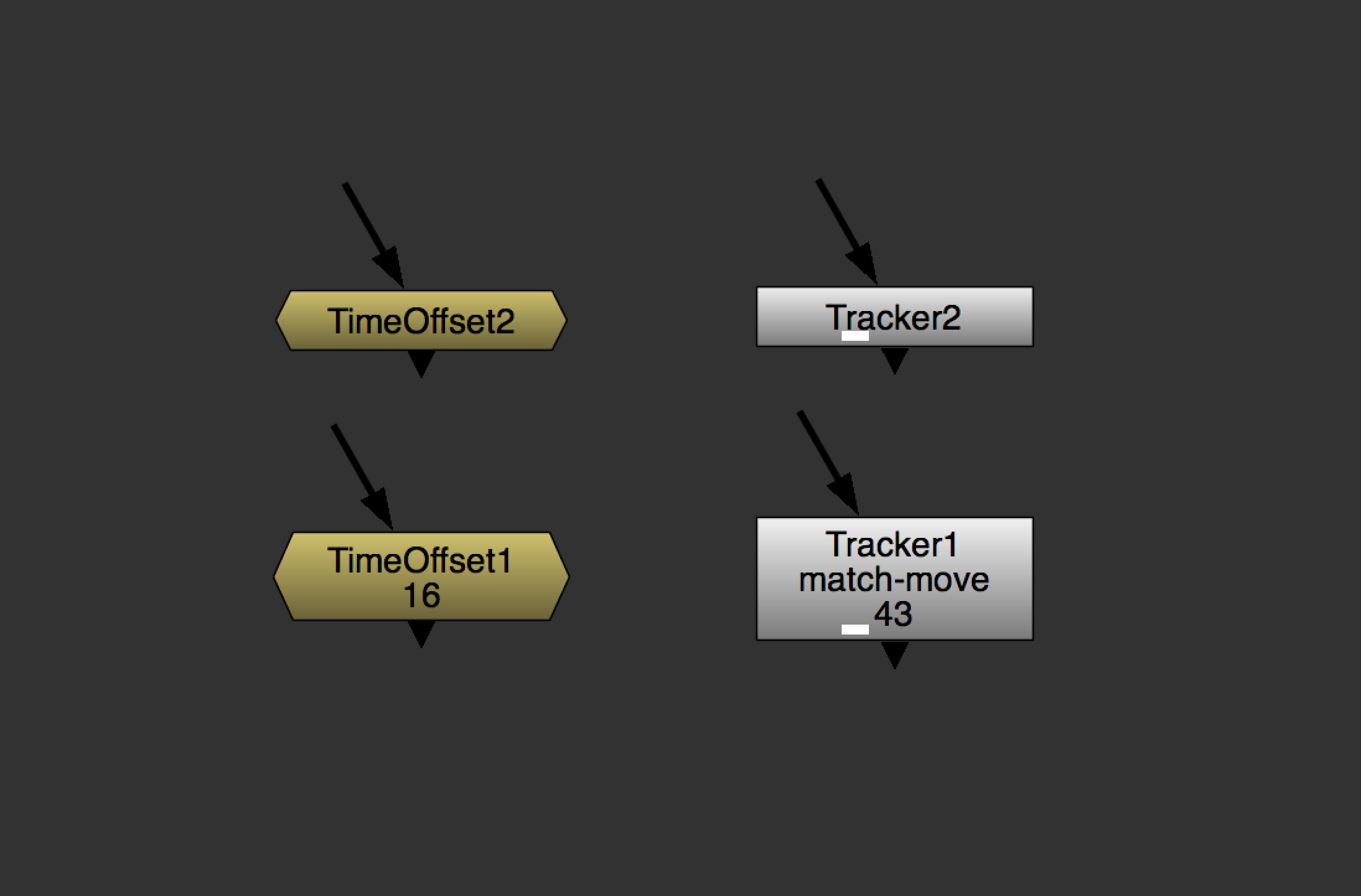
But I couldn't just Clone a Transform and paste it into the other branches. The problem being that none of the elements shared the same Anchor Point (Center). If I cloned the Transform, all of the graphics would be scaling from the center of the first element, not their own centers.
I needed a handful of Transforms that were linked by all of their parameters except Center.
So, rather than spending 15 minutes writing and copy/pasting expressions to link all of the various knobs on the Transform nodes, I spent an hour writing a Python tool that will do it with a keyboard shortcut.
def CopyWithExp():
sourceNode = nuke.selectedNode().name()
nuke.nodeCopy("%clipboard%")
nuke.nodePaste("%clipboard%")
destNode = nuke.selectedNode().name()
for i in nuke.selectedNodes():
for j in i.knobs():
i[j].setExpression( sourceNode + '.' + j )
i['xpos'].setExpression('')
i['ypos'].setExpression('')
i['selected'].setExpression('')
i['channels'].setExpression( sourceNode + '.channels' )
nuke.menu('Nuke').addCommand('Edit/Copy with Expressions', "CopyWithExp()", "^#C")(This goes in your Menu.py file in your ./nuke directory.)
Now, when I press ⌥+⌘+C, it will duplicate the selected node, and link every knob with an expression. Essentially a DIY Clone, but with the ability to easily "declone" individual parameters by right clicking on the parameter and selecting Set to default.
What's Up With That Extra Junk In The For Loop?
It wouldn't be a homemade tool if it didn't include some hacky code to fix some unexpected results. As it turns out, when you programmatically link every knob from one node to another, you also end up linking the hidden knobs that are not exposed to the user in the GUI. Which is not always good.
In the for loop above, you'll see that, after linking every knob between the old and new nodes, I'm reverting the parameters for xpos, ypos, and selected. These parameters are the x and y position of the node on the node graph, and whether or not the node has been selected.
For obvious reasons, we'd like the ability to select the nodes individually. And, if we don't unlink the x and y positions of the nodes, the new node will be permanently affixed atop the old node. You won't even be able to see the original node. Not super helpful.
I've also "manually" linked the channels knob. For some reason, it was not expression linking correctly on its own. It would end up linked to the channel knob, which is a different thing entirely. So, rather than figuring out why it wasn't working, I lazily fixed it with an extra line of code.
Does It Work With Nodes That Aren't Transform Nodes?
Yes, it does. But you may discover a node that has a parameter that breaks in the duplication, like the channels knob did in the Transforms. If/when you find a broken knob, you can add it to the "whitelist" of parameters at the end of the for loop and so on, and so on.
If you'd like to do some exploring, you can see a full list of the knobs associated with a node by firing up Nuke's Script Editor and running the following command while the node is selected:
for i in nuke.selectedNode().knobs():
print iUgh. Are There Any Other Limitations?
There totally are.
Being that the new nodes created are linked via expressions, copying the nodes into a new Nuke project will result in the same error message one would see copying any expression linked node into a new script. It will complain that it can't find the source node that the expressions are looking for. Even if you copy the source node with the expression linked nodes, it will throw an error, then, when you dismiss the error message, the nodes will work. Nuke.
Also, the nuke.nodeCopy("%clipboard%") and nuke.nodePaste("%clipboard%") commands in the Python script use the system clipboard to duplicate the node. This isn't different than using the normal system copy and paste tools in Nuke, but some of you out there use weird clipboard utilities that do things I can't predict. So. There's not much I can do for you there.
Anyway
This tools comes from a conversation I had with friend-of-the-blog, and my podcast co-host, Joe Steel. I was complaining about this problem (and others) in our Slack channel, and he mentioned that Katana had a Copy with Expressions command that would do what I was asking.
I'm actually surprised this feature isn't already built in to Nuke, but now, thanks to Joe, all of our Expression-Linked Dreams have come true.